
برای درک یادگیری تقویتی (Reinforcement Learning) یا به اختصار RL، بیایید با تصویر بزرگ شروع کنیم.
تصویر بزرگ
ایده پشت یادگیری تقویتی این است که یک عامل (یک هوش مصنوعی) از طریق تعامل با محیط (از طریق آزمون و خطا) و دریافت پاداش (منفی یا مثبت) به عنوان بازخورد برای انجام اقدامات، از محیط بیاموزد.
یادگیری از تعامل با محیط از تجربیات طبیعی ما ناشی میشود.
به عنوان مثال، تصور کنید که برادر کوچک خود را در مقابل یک بازی ویدیویی که هرگز بازی نکرده بود قرار دهید، یک کنترلر به او بدهید و او را تنها بگذارید.

برادر شما با فشار دادن دکمه سمت راست (اکشن) با محیط (بازی ویدیویی) تعامل خواهد داشت. او یک سکه گرفت، این یک جایزه +۱ است. این مثبت است، او فقط فهمید که در این بازی باید سکهها را بدست آورد.
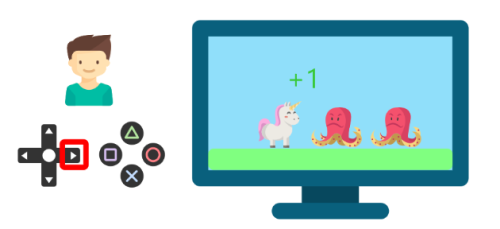
اما بعد، دوباره دکمه سمت راست را فشار میدهد و دشمن را لمس میکند. او به تازگی مرده است، بنابراین این یک پاداش -۱ است.

با تعامل با محیط خود از طریق آزمون و خطا، برادر کوچک شما میفهمد که باید در این محیط سکه بگیرد اما از دشمنان دوری کند.
بدون هیچ نظارتی، کودک در بازی بهتر و بهتر میشود.
این گونه است که انسانها و حیوانات از طریق تعامل یاد میگیرند. یادگیری تقویتی فقط یک رویکرد محاسباتی یادگیری از اقدامات است.
یک تعریف رسمی از یادگیری تقویتی
اکنون میتوانیم یک تعریف رسمی داشته باشیم:
یادگیری تقویتی چارچوبی برای حل وظایف کنترلی (مشکلات تصمیم گیری نیز نامیده میشود) با ساختن عواملی است که از طریق تعامل با محیط از طریق آزمون و خطا و دریافت پاداش (مثبت یا منفی) به عنوان بازخورد منحصر به فرد، از محیط یاد میگیرند.
منبع