در ابتدا تصویری از فرایند یادگیری تقویتی (RL) را ببینیم:
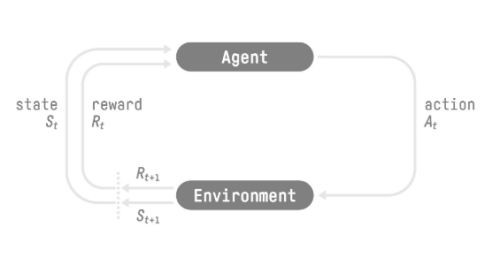
فرایند یادگیری تقویتی: یک حلقه از حالت یا وضعیت (state)، عمل یا اقدام (action)، پاداش (reward) و حالت بعدی (next state).
برای درک فرایند یادگیری تقویتی، یک عامل را تصور کنیم که در حال یادگیری بازی پلتفرمی است:
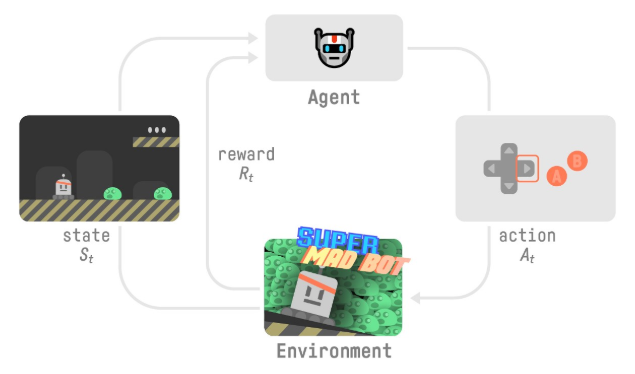
- عامل، حالت S0 را از محیط میگیرد-اولین فرِیم از بازی خود را دریافت میکنیم (محیط)
- طبق حالت S0، عامل، عمل A0 را برمیگزیند-عامل ما به سمت راست حرکت میکند.
- محیط به حالت جدید S1 میرود-فرِیم جدید.
- محیط تعداد پاداش R1 به عامل میدهد-ما نمردیم (پاداش مثبت +۱).
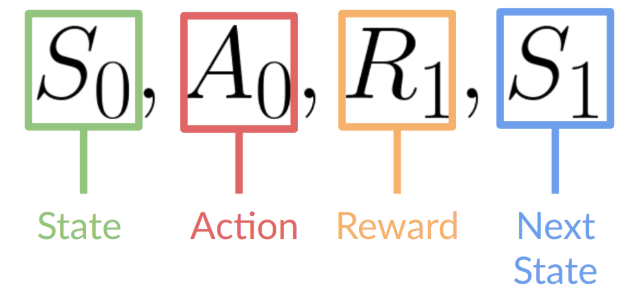
خروجیهای این فرایند یادگیری تقویتی ترتیبی از حالت، عمل، پاداش و حالت بعدی است.
هدف عامل به حداکثر رساندن پاداش انباشته خود است که بازده مورد انتظار نامیده میشود.
فرضیه پاداش: ایده اصلی یادگیری تقویتی
⇐ چرا هدف عامل به حداکثر رساندن بازده مورد انتظار است؟
زیرا RL بر اساس فرضیه پاداش است، یعنی همه اهداف را میتوان به عنوان حداکثر کردن بازده مورد انتظار (پاداش تجمعی مورد انتظار) توصیف کرد.
به همین دلیل است که در فرایند یادگیری تقویتی، برای داشتن بهترین رفتار، هدف ما این است که یاد بگیریم اقداماتی را انجام دهیم که پاداش تجمعی مورد انتظار را به حداکثر برسانند.
فرایند مارکوف (Markov)
در مقالات، خواهید دید که فرآیند یادگیری تقویتی یک فرآیند تصمیم گیری مارکوف (MDP) نامیده میشود.
ما در این مقاله بهصورت کلی اشارهای به فرایند مارکوف میکنیم:
ویژگی مارکوف به این معنی است که عامل ما فقط به وضعیت فعلی نیاز دارد تا تصمیم بگیرد چه اقدامی انجام دهد و نه تاریخچه همه حالات و اقداماتی که قبلا انجام داده است.
مشاهدات/فضای حالتها
مشاهدات/حالتها اطلاعاتی هستند که عامل ما از محیط دریافت میکند. در مورد یک بازی ویدیویی، میتواند یک فریم (یک اسکرین شات) باشد. در مورد عامل معاملاتی میتواند ارزش یک سهم خاص و غیره باشد.
با این حال، تفاوتی بین مشاهده و حالت وجود دارد:
- حالت s: توصیف کاملی از وضعیت جهان است (هیچ اطلاعات پنهانی وجود ندارد). در یک محیط کاملاً مشاهده شده.

در بازی شطرنج، از آنجایی که به کل اطلاعات تخته دسترسی داریم، یک حالت از محیط دریافت میکنیم.
در یک بازی شطرنج، ما به کل اطلاعات تخته دسترسی داریم، بنابراین یک حالت از محیط دریافت میکنیم. به عبارت دیگر محیط به طور کامل رعایت میشود.
- مشاهده o: توصیف جزئی از حالت است. در یک محیط نیمه مشاهده شده.

در Super Mario Bros، ما فقط قسمتی از سطح نزدیک به بازیکن را میبینیم، بنابراین یک مشاهده دریافت میکنیم.
در Super Mario Bros، ما در یک محیط نیمه مشاهده شده قرار داریم. ما یک مشاهده دریافت میکنیم زیرا فقط بخشی از سطح را میبینیم.
در این مقاله از عبارت “حالت” برای اشاره به حالت و مشاهده استفاده میکنیم، اما در پیادهسازیها تمایز قائل میشویم.
فضای عمل
فضای عمل، مجموعهای از تمام اقدامات ممکن در یک محیط است.
اقدامات میتوانند از یک فضای گسسته یا پیوسته انجام شوند:
- فضای گسسته: تعداد اقدامات ممکن محدود است.
در Super Mario Bros، ما فقط ۴ عمل ممکن داریم: چپ، راست، بالا (پریدن) و پایین (قوز کردن).
باز هم، در Super Mario Bros، ما مجموعه محدودی از اقدامات را داریم زیرا ما فقط ۴ جهت داریم.
- فضای پیوسته: تعداد اعمال ممکن بینهایت است.

یک عامل خودروی خودران تعداد بینهایتی از اقدامات ممکن دارد زیرا میتواند ۲۰ درجه، ۲۱،۱ درجه، ۲۱،۲ درجه، بوق، ۲۰ درجه به راست بپیچد…
در نظر گرفتن این اطلاعات بسیار مهم است زیرا در انتخاب الگوریتم RL در آینده اهمیت خواهد داشت.
پاداش و تخفیف
پاداش در یادگیری تقویتی، عنصری اساسی است زیرا تنها بازخورد برای عامل است. به لطف آن، عامل ما میداند که آیا اقدام انجام شده خوب بوده است یا خیر.
پاداش تجمیع شده در هر مرحله زمانی t را میتوان به صورت زیر نوشت:

پاداش تجمیع شده برابر است با مجموع تمام پاداشها در دنباله.
که معادل است با:
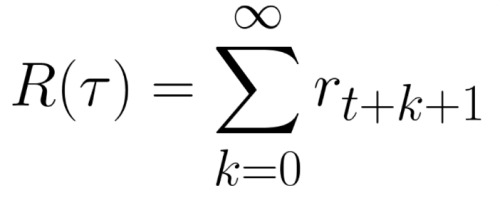
پاداش تجمیع شده=rt+1 (rt+k+1 = rt+0+1 = rt+1)+ rt+2 (rt+k+1 = rt+1+1 = rt+2) + …
با این حال، در واقعیت، ما نمیتوانیم آنها را به این شکل اضافه کنیم. پاداشهایی که زودتر میآیند (در ابتدای بازی) به احتمال زیاد اتفاق میافتند زیرا قابل پیش بینیتر از پاداش بلند مدت آینده هستند.
فرض کنید عامل شما این موش کوچک است که میتواند در هر مرحله یک کاشی را حرکت دهد و حریف شما گربه است (که میتواند حرکت کند). هدف موش خوردن حداکثر پنیر قبل از خوردن توسط گربه است.

همانطور که در نمودار میبینیم، خوردن پنیر نزدیک ما بیشتر از پنیر نزدیک به گربه است (هرچه به گربه نزدیکتر باشیم، خطرناکتر است).
در نتیجه، پاداش نزدیک گربه، حتی اگر بزرگتر باشد (پنیر بیشتر)، تخفیف بیشتری خواهد داشت زیرا ما واقعاً مطمئن نیستیم که بتوانیم آن را بخوریم.
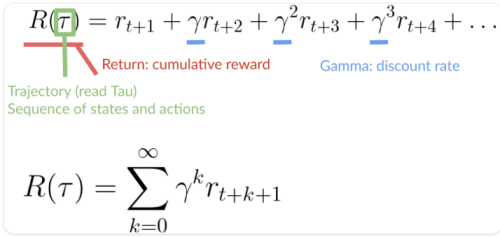
برای تقلیل پاداشها به صورت زیر عمل میکنیم:
- ما یک نرخ تقلیل به نام گاما تعریف میکنیم. باید بین ۰ و ۱ باشد. بیشتر اوقات بین ۰.۹۵ و ۰.۹۹.
- هر چه گاما بزرگتر باشد، تقلیل کمتر است. این بدان معناست که عامل ما بیشتر به پاداش بلند مدت اهمیت میدهد.
- از طرف دیگر، هر چه گاما کوچکتر باشد، تقلیل بیشتر است. این بدان معناست که عامل ما بیشتر به پاداش کوتاه مدت (نزدیکترین پنیر) اهمیت میدهد.
2. سپس، هر پاداش با گاما به نماگر مرحله زمانی تقلیل داده میشود. با افزایش گام زمانی، گربه به ما نزدیکتر میشود، بنابراین پاداش آینده کمتر و کمتر اتفاق میافتد.
پاداش تجمعی مورد انتظار ما با تقلیل:
منبع: https://huggingface.co/learn/deep-rl-course/unit1/rl-framework